Improve SEO with Robots.txt and the sitemap
Describes how to improve search with robots.txt and the sitemap in Optimizely Configured Commerce.
Creating a Robots.txt file allows search crawlers to accurately find and identify the website's sitemap while also reducing the potential workload to the site. If a Robots.txt file is not included, the sitemap will need to be submitted manually to the search engine directly.
Submit your sitemap via the search engines submission interface
To submit your sitemap directly to a search engine, which will enable you to receive status information and any processing errors, refer to each search engine's documentation.
Specify the sitemap location in your Robots.txt file
To specify the location of the sitemap using a robots.txt file add the following line, including the full URL, to the sitemap:
- Sitemap:
http://www.example.com/sitemap.xml
Because the directive is independent of the user agent-line, it can be place anywhere in the file. If a sitemap index file exists, its location can be included in the file. Each sitemap does not need to be included into the file. However, if you want to specify more than one sitemap per robots.txt file, add the following URL to the file.
- Sitemap:
http://www.example.com/sitemap-host1.xml - Sitemap:
http://www.example.com/sitemap-host2.xml
Submit a sitemap via an HTTP request
HTTP requests perform an action on a specific server resource. Submitting a sitemap request via a HTTP request ensures that the site will be index by the search engine.
To submit a sitemap using an HTTP request replace <searchengine_URL> with the URL provided by the specific search engine.
To issue a request <searchengine_URL>/ping?sitemap=sitemap_url
For example, if a Sitemap is located at http://www.example.com/sitemap.gz, your URL will become:
<searchengine_URL>/ping?sitemap=http://www.example.com/sitemap.gz
URL encode everything after the /ping?sitemap=
<searchengine_URL>/ping?sitemap=http%3A%2F%2Fwww.yoursite.com%2Fsitemap.gz
The HTTP request can be issued using wget, curl, or another content retriever. A successful request will return an HTTP 200 response code; if you receive a different response resubmit your request. The HTTP 200 response code indicates that the search engine has received the sitemap. However, the returned HTTP 200 code does not validate the sitemap or the URL. To ensure validation to set up an automated job to generate and submit sitemaps on a regular basis.
NoteIf submitting a sitemap index file only one HTTP request that includes the location of the sitemap index file needs to issued. It is not necessary to issue individual requests for each sitemap listed in the index.
Edit the robot.txt file
The robots.txt file prevents web crawlers, such as Googlebot, from crawling certain pages of your site. The file contains a list commands and URLs that dictate the behavior of web crawlers on a website. Keep in mind that not all web crawlers adhere to the directives in the robots.txt. There are several ways to make edits to the Robots.txt file. This article provides the steps for editing the robots.txt file through the Content Management System (CMS).
-
Go to the Admin Console.
-
Click View Website.
-
Toggle Content Editor to display On.
-
Select the desired website from the list of websites.
-
Click Content Tree.
-
Click Edit.
-
Click Home and expand the content tree.
-
Click the Robots.txt file.
-
Click Edit this page to make edits to the page.
NoteThe robots.txt file, may already contain some sitemap URLs which are generated by the system and cannot be edited.
-
In the Text field, if necessary, add the Disallow: / command and click enter or return to move to the next line.
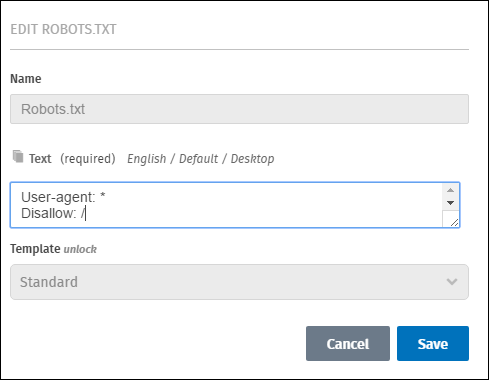
-
Add the desired URLs that should be ignored by web crawlers. Enter each URL on its own line and spaces between lines are not necessary.
NoteThe URLs need to be preceded by sitemap:. For example: sitemap
https://website.com/pagename -
After all desired URLs have been added, click the Save button. The newly added URLs now appear on the page.
-
Click Publish.
-
In the Publishing window, decide whether to publish immediately or sometime in the future. Click Publish.
Updated 5 months ago