
Crawl product pages
Describes how search engines crawl product pages.
Search engines use automated bots to crawl content of your website. These bots update the search engine records for web content and search indices of your website.
Optimizely Configured Commerce has a Search Engineering Optimization (SEO) feature that allows bots to consume server-side rendered content instead of the dynamically rendered Angular pages.
The following table represents the crawlers that will trigger the SEO Catalog:
| Crawler | Crawler Description |
|---|---|
| bot | This substring will catch all crawlers with "bot" in the UserAgent |
| crawler | This substring will catch all crawlers with "crawler" in the UserAgent |
| baiduspider | Baidu's web crawling spider |
| 80legs | 80 legs web crawling and screen scraping platform |
| ia_archiver | Alexa's web and site audit crawler |
| voyager | Cosmix Corporation's web crawling bot |
| curl | Command-line tool for transferring data |
| wget | Command-line tool for retrieving files |
| yahoo! Slurp | Yahoo!'s web-indexing robot |
| mediapartners-google | Google's web-indexing robot |
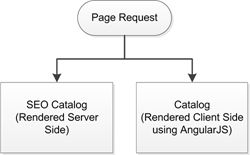
From a coding standpoint, the logic is handled in the SearchCrawlerRouteConstraint class located in the InSite.Mvc.Infrastructure assembly. The Match method returns a Boolean response of whether or not the incoming request, specifically the User Agent object, contains any of the crawlers listed above.
This approach is required due to the use of Angular JS in the Configured Commerce front end.
When deploying and testing your website we recommend using a browser, such as Chrome, with developer tools enabled. This way you can spoof the User Agent value to test your SEO settings. Press F12, click Configure throttling, and select the Custom user agent of your choosing.
For information about Device Emulation with Google, see Google developer site.
Updated 4 months ago