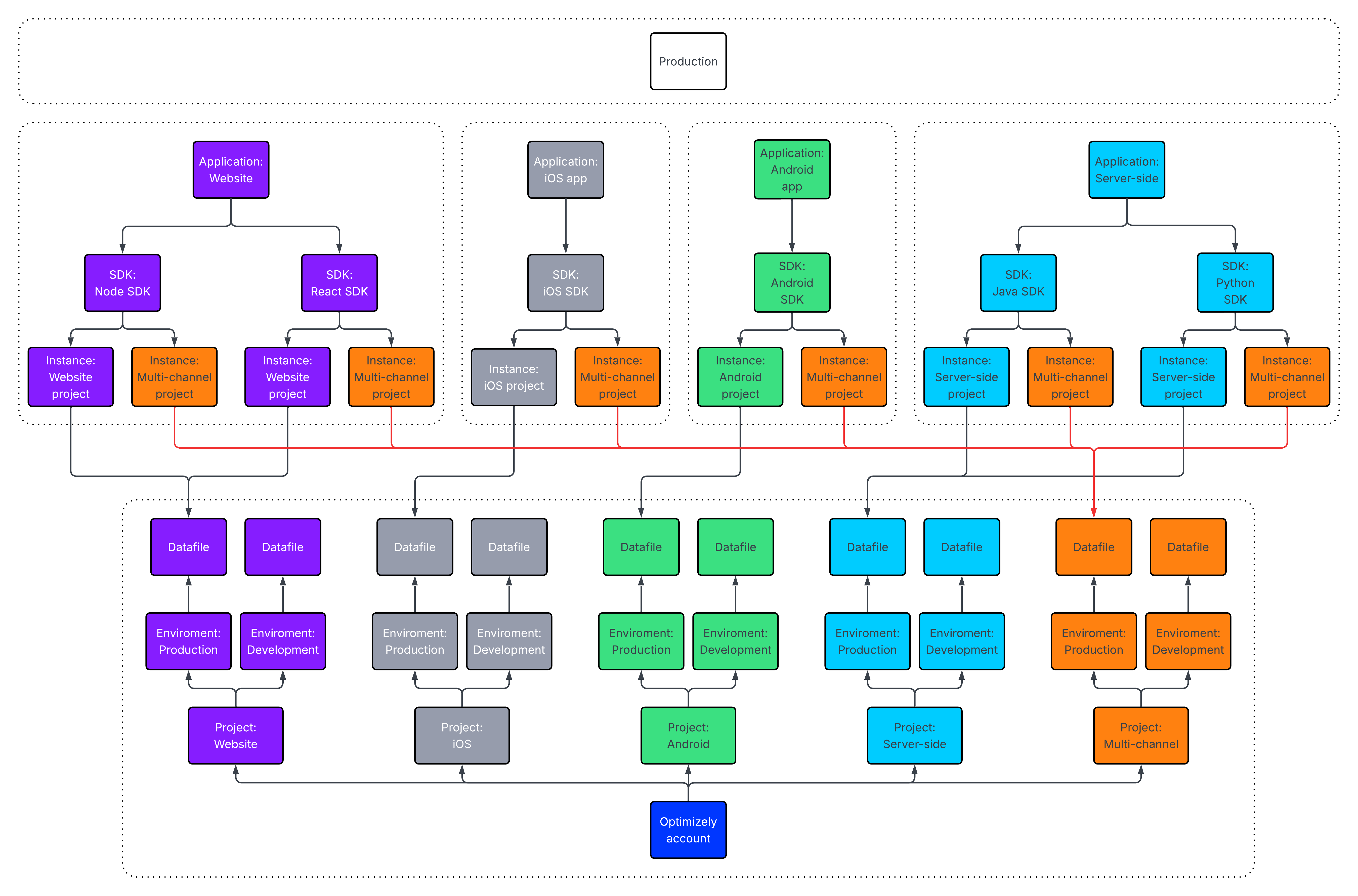
Multiple SDK implementations
This topic describes best practices for using multiple Optimizely Feature Experimentation SDKs.
In more complex codebases, a single customer interaction often involves multiple services and languages. For example, you may want to
- Use a server-side SDK to run an experiment on your backend, but track results with conversion events using one or more client-side SDKs (JavaScript, iOS, or Android).
- Run an experiment spanning multiple services written in different languages. For example, when using a microservice architecture or migrating from an old stack to a new one.
Optimizely Feature Experimentation provides SDKs for most major languages. This guide describes common use cases for multiple languages, demonstrates how to get started with multiple languages, and addresses some common implementation questions.
Download the necessary SDK version
If you plan to use multiple SDKs, you should use SDK versions released after April 2018 (version 2.0 or later for most of the SDKs). These versions generate a v4 datafile with full Feature Management support that works across all version 2.0 SDKs.
If you need help choosing the correct SDK version or versions for your particular implementation, contact Optimizely Support.
Pre-2.0 projects
NoteThe Flutter, Swift, React and Go SDKs were released at different times, so their versioning is different than the rest of the SDKs.
If you have existing projects using pre-2.0 SDK versions released before April 2018, you can still use them across multiple languages. However, there are some important restrictions.
- You cannot experiment across Full Stack and Mobile projects. Pre-2.0 Full Stack and Mobile projects generate incompatible datafiles (v2 and v3, respectively).
- You cannot use Feature Management with existing Mobile projects. To use Feature Management with Mobile, install a 2.x or 3.x SDK and determine if you need to create a new project.
Consistent bucketing and why it matters
The SDKs use MurmurHash3 to determine whether a user is bucketed into an experiment and, if so, which variation they receive. This is based on the user ID and the experiment ID. The bucketing code is shared across SDKs.
This means bucketing is deterministic. You get the same result when bucketing a given user ID into a given experiment, which is consistent across SDKs. For example, given a common datafile, you get the same result bucketing user ID abc into experiment 123 with the Python SDK as with any other SDK.
This behavior is the core of Optimizely's support for multiple languages. However, it relies on three assumptions.
- You must use the same datafile across SDKs. Learn more about managing the datafile.
- You must use the same user ID and attributes when bucketing a user across SDKs. If all your SDKs use the same deterministic method to generate user IDs, then you are ready. However, if you use random user IDs, you must pass these from the server to any client SDKs. See Sharing user IDs and attributes with client SDKs.
- If you use a User Profile Service with one SDK, you must implement it consistently across all SDKs. For example, if you implement a user profile service on your iOS client (this is the default behavior) but not on your Ruby backend, and you change traffic allocation for a running experiment, some users would be bucketed inconsistently across client and server. To avoid this, you would have to implement the same user profile service in your Ruby backend as well.
Bucket 'at the source' for server-side experiments
Because of the deterministic and consistent nature of bucketing, it is acceptable to bucket users multiple times across SDKs. However, when experimenting across server-side and client-side SDKs, you might find it helpful to bucket users on the server side to ensure a consistent experience.
- If your client does not have access to the user ID or attributes needed for bucketing, you can bucket users on the server and then pass along the decision and data required to the client.
- If you maintain many different client SDKs across other platforms, it may lighten your implementation workload to consolidate bucketing.
Share user IDs and attributes with client SDKs
When using both client and server SDKs, it may be necessary to pass the user ID from the server to the client to ensure proper conversion event tracking. You may also want to pass along user attributes only available on the server for tracking conversion events.
While there is no one-size-fits-all approach for this, you should use HTTPS-only cookies (meaning cookies with the Secure flag set). When handling a request from a new user, the server assigns a user ID, buckets the user, and runs the variation code (if necessary). It then sets a Secure cookie in the response, containing the user ID and any necessary attribute data. The client SDK then reads this cookie to create an OptimizelyUserContext object for tracking events. You can use this approach with both JavaScript and iOS or Android SDKs.
Share the datafile with client SDKs
Most customers find that as long as each SDK implementation has a relatively short cache expiration, occasional brief discrepancies between datafiles are okay. However, if you need to ensure strict consistency, you can sync the datafile between the client and server. This lets both instantiate an Optimizely client from exactly the same datafile. This eliminates any risk of inconsistencies that could be introduced by the client and server each fetching the datafile separately from the Optimizely CDN at different times. For example, if the CDN were in the process of propagating updates from the Optimizely app just as the client and server separately fetched the datafile.
In this approach
- The server instantiates using a datafile fetched from the Optimizely CDN.
- The server retrieves a JSON representation of its datafile, using the
OptimizelyConfigobject'sgetDatafilemethod. For example:const datafile = optimizelyClientInstance.getOptimizelyConfig().getDatafile(); - The server passes the datafile to the client, for example, as part of a rendered HTML page.
- The client instantiates from the passed datafile.
The benefits of this approach are the following:
- Mitigates flickering scenarios – If the datafile contents live inline in the page source, the client instantiation does not have to wait until the XHR fetch is complete.
- Better performance – Fewer requests during page load results in faster page rendering (first meaningful paint).
The downside to this approach is that you must build a server-side solution for capturing fresh datafiles and persisting them to the client side.
Example: Server-side variation code with client-side conversion tracking
The most common use case for multiple languages is executing variation code on the server and measuring the effects of those changes on the client. The following is a basic example of this use case.
ImportantThis server or client use case is not compatible with secure environments. For information, see secure environments.
In this example, you have a JavaScript single-page app ecommerce site, and you are running an experiment in the Optimizely Python server code on the sorting algorithm for the product list. You want to see if this experiment affects how often users add items to their carts on your site. You use the Python SDK to run the experiment and the JavaScript SDK to track conversion events.
To get started, complete the following.
- Configure a new Feature Experimentation project. Use the Python backend to assign users to variations, so the project's primary language should be Python.
- Install and configure the latest versions of the necessary SDKs on the server and clients, then point them to your project's datafile. Install the Python SDK on the server and use npm to install the JavaScript SDK in your single-page app.
- Create an experiment and a conversion event. Create an experiment based on a flag called
product_sortwith two variations,popular_firstandfeatured_first. Create an eventuser_added_to_cartto track the goal of the experiment. - Determine if you need to pass user IDs and attributes from the server.
- User IDs – If both the server and client have access to stable, consistent user IDs for everyone in your experiments, you can use that as the user ID. For example, if your experiment only affects logged-in users, and both the client and server know the user's unique ID in the database, you could use that as the user ID for the activate calls on the server and track calls on the client. In any other case, you need to pass the user ID from the server.
- User attribute – Do you want to track any user attributes with a conversion event, and are any of them unavailable on the client? If so, you need to pass them from the server.
- Pass user IDs and attributes from the server to the client if necessary. See Sharing user IDs and attributes with client SDKs.
- Use the passed user ID and attributes to create a user context. Call the decide method on that user on the server to bucket users and execute variation code. In this example, you make decisions for
product_sorton the Python server and sort the product list depending on which variation is returned. - Use the Track Event method on the client to track conversion events. Next, you would configure your JavaScript client app to track the
user_added_to_cartevent every time a user adds an item to their cart.
Updated 3 months ago