Implementation checklist
Important configuration details and best practices to employ while using Optimizely Feature Experimentation.
Before implementing Optimizely Feature Experimentation in a production environment, review the configuration details and best practices checklist to simplify implementation.
Architectural diagrams
The following diagrams demonstrate how you, your users, and Optimizely Feature Experimentation interact. Understanding these interactions is crucial for implementing Feature Experimentation effectively. Click on any diagram to enlarge it.
Overall architectural diagram
The overall architectural diagram provides a detailed view of Feature Experimentation's components and their interactions, illustrating how data flows between key entities. The diagram contains the following three main sections: Your implementation, Optimizely UI, and the Optimizely servers. It shows how these sections work together to support feature flagging and experimentation. It highlights interactions between components using Crow's foot relationship notation, a standard entity-relationship (ER) modeling technique that visually represents the types of relationships, such as 'one' or 'many,' between different parts of the application and event processing. See the key following the diagram.
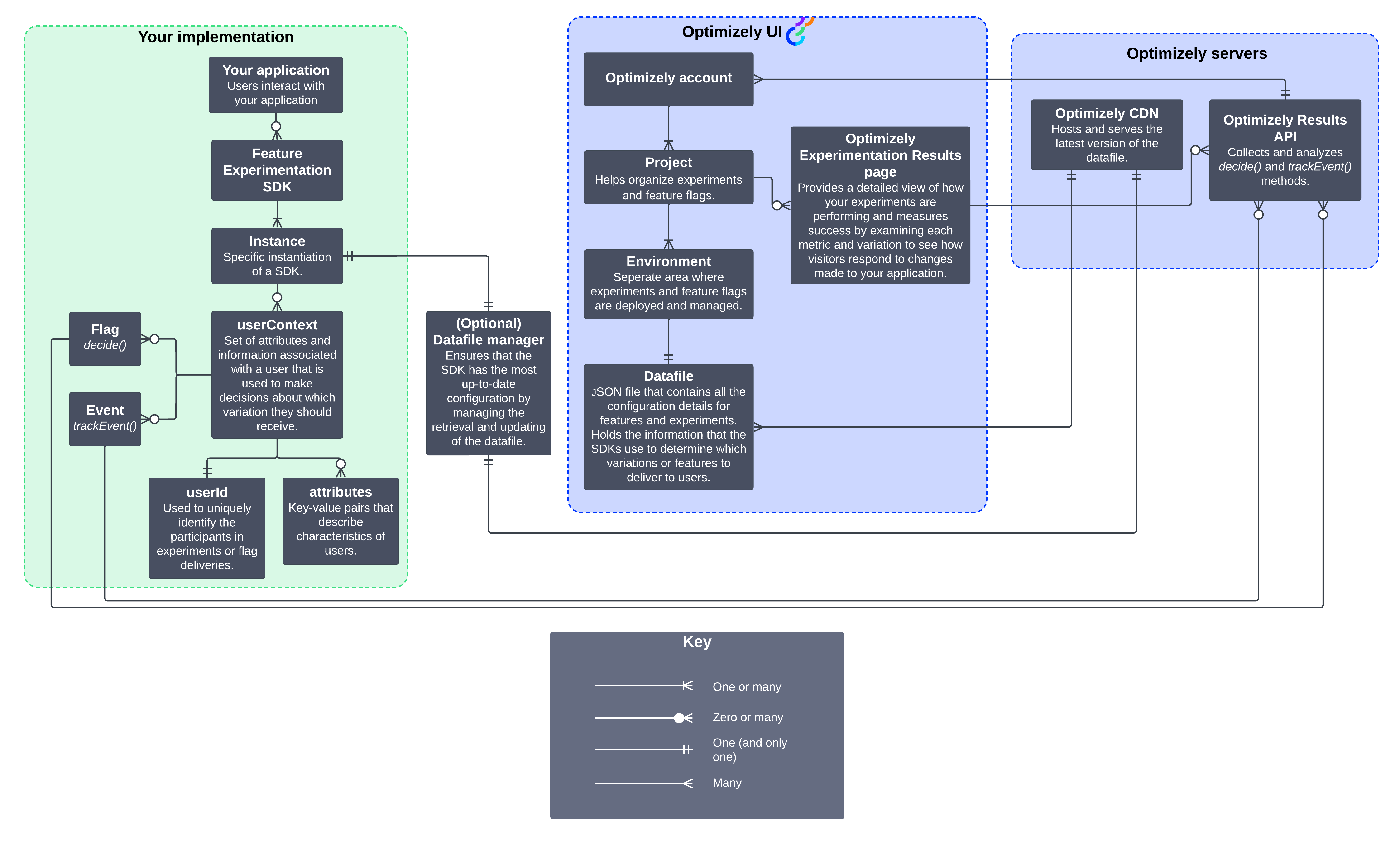
System context diagram
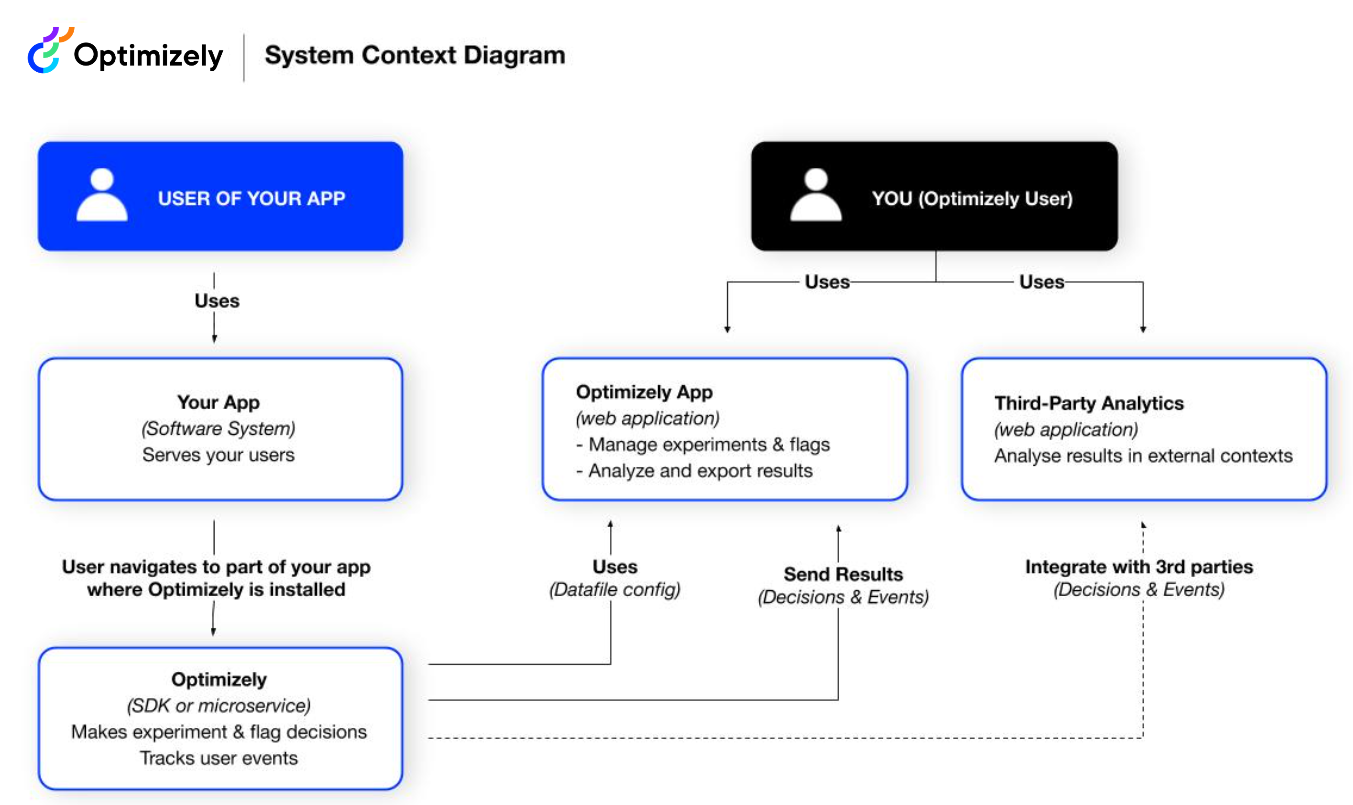
The system context diagram shows how your application interacts with Optimizely and third-party analytics systems. It highlights how applications send event data to Optimizely, how decision data flows back, and how integrations with analytics platforms provide experimentation insights.
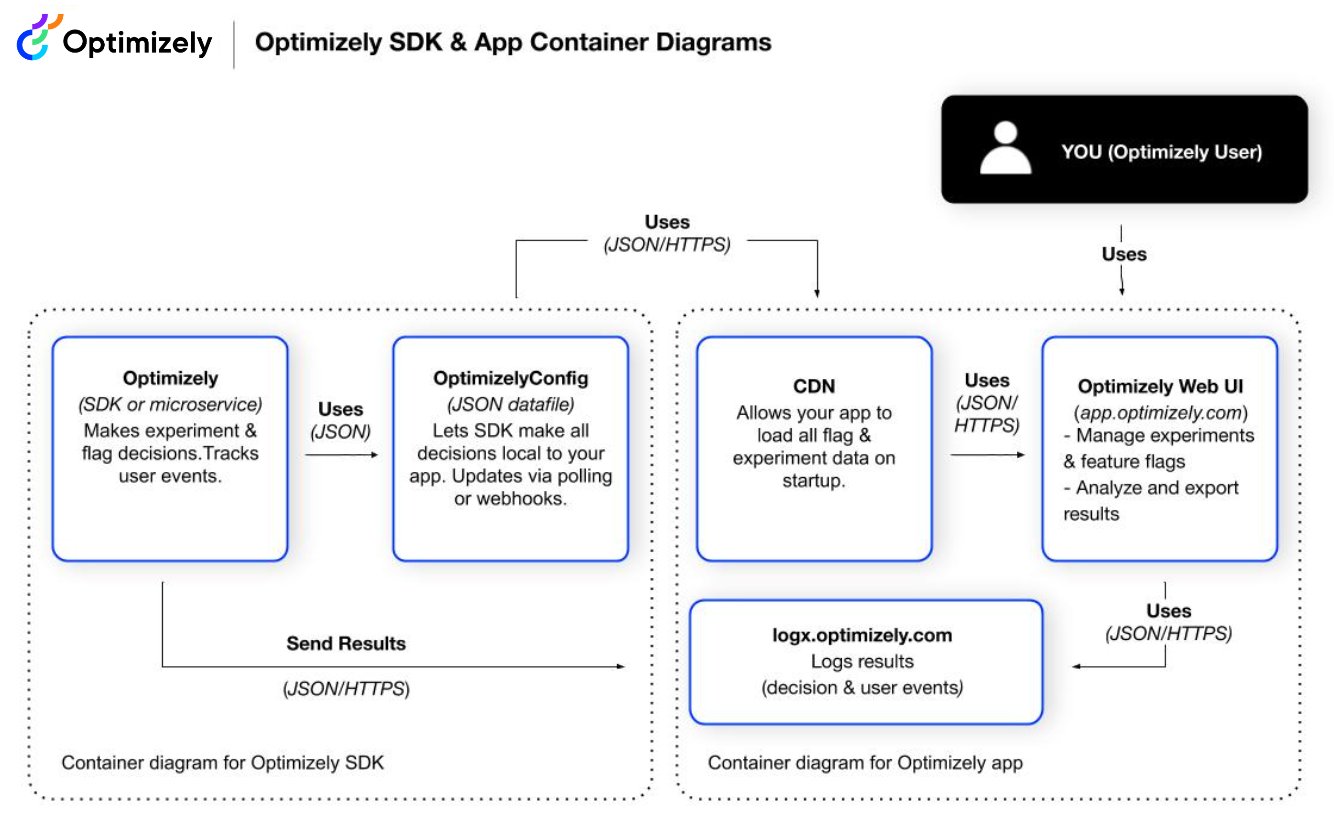
Feature Experimentation SDK and app container
The SDK and app container diagram shows how the SDKs integrate within your application to evaluate feature flags and experiments. It covers feature configuration, decision-making, and event tracking. Network requests use JSON over HTTPS, and internal data exchanges use JSON.
Datafile management
The datafile is a JSON representation of the OptimizelyConfig. It contains the data needed to deliver and track your experiments and flag deliveries for an environment in your Optimizely Feature Experimentation project.
You have the following options for syncing the datafile between your Feature Experimentation project and your application:
- Pull method (recommended) – The Feature Experimentation SDKs automatically fetch the datafile at a configurable polling interval.
- Push method – Webhooks fetch and manage datafiles based on application changes. Use this method alone or in combination with polling if you need faster updates.
- Custom method – Fetch the datafile using the Optimizely CDN datafile URL.
Other important considerations for datafile management include the following:
- Caching and persistence.
- Synchronization between SDK instances.
- Network availability.
NoteTo ensure webhook requests originate from Optimizely, secure your webhook using a token in the request header.
SDK configuration
The Feature Experimentation SDKs are configurable to meet the needs of any production environment. However, adequate scaling may require overriding some default behavior to better align with your application's needs.
Logger
Each SDK includes a logger framework that does nothing by default. You should create a custom logger and pass it to the Optimizely client. For example, you can write logs to an internal logging service or a third-party vendor.
For information, see the documentation for the logger and the SimpleLogger reference implementation.
Error handler
In a production environment, you must handle errors consistently across the application. The Optimizely Feature Experimentation SDKs let you provide a custom error handler to catch configuration issues like an unknown experiment key or unknown event key. This handler should let the application fail gracefully, maintaining a normal user experience. It should also send alerts to an external service, such as Sentry, to alert the team of an issue.
ImportantIf you do not provide a handler, errors do not surface in your application.
User profile service
Building a user profile service (UPS) helps maintain consistent variation assignments between users when test configuration settings change.
The Optimizely Feature Experimentation SDKs bucket users using a deterministic hashing function. This means that the user evaluates to the same variation as long as the datafile and user ID are consistent. However, when test configuration settings are updated (such as adding a new variation or changing traffic allocation), the user's variation may change and alter the user experience. See How bucketing works in Optimizely Feature Experimentation.
A UPS solves this by persisting information about the user in a datastore. At a minimum, your UPS should create a mapping of user ID to variation assignment. Implementing a UPS requires exposing a lookup and save function that returns or persists a user profile dictionary. This service relies on consistent user IDs across all use cases and sessions.
NoteYou should cache the user information after the first lookup to speed up future lookups.
For example, using Redis or Cassandra for the cache, you can store user profiles in a key-value pair mapping. You can use a hashed email address mapping to a variation assignment. To keep sticky bucketing for six hours, set a time to live (TTL) on each record. As Optimizely buckets each user, the UPS interfaces with this cache and makes reads and writes to check assignments before bucketing normally.
Build an SDK wrapper
Many developers use wrappers to encapsulate SDK functionality and simplify maintenance. You can do this for the previous configuration options.
Environments
Optimizely Feature Experimentation's environments lets you confirm behavior and run tests in isolated environments, like development or staging. This makes it easier to deploy tests in production safely. Environments are customizable and should mimic your team's workflow. Most customers use two environments, development and production. This lets engineering and QA teams inspect tests safely in an isolated setting while site visitors are exposed to tests running in the production environment.
View production as your real-world workload. A staging environment should mimic all aspects of production so you can test before deployment. In these environments, all aspects of the SDK, including the dispatcher and logger, should be production-grade. In local environments like test or development, it is okay to use the out-of-the-box implementations instead.
Environments are kept separate and isolated from each other with their own datafiles. For added security, Optimizely Feature Experimentation lets you create secure environments, which require authentication for datafile requests. The Feature Experimentation server-side SDKs support initialization with these authenticated datafiles. You should use these secure environments only in projects that exclusively use server-side SDKs and implementation. If you fetch the datafiles in a client-side environment, they may become accessible to end-users.
Clock synchronization
Optimizely Feature Experimentation runs on Google Cloud Platform (GCP) infrastructure. All server-side timestamps use Coordinated Universal Time (UTC). Infrastructure clocks sync using the Network Time Protocol (NTP) via Google's time service across all servers. This ensures audit logs, security events, experiment data, and forensic analysis records maintain consistent and accurate timestamps across the platform.
Infrastructure clock sync
Optimizely syncs all infrastructure clocks to an accurate and authoritative time source using the following approach:
- Time protocol – NTP via Google Cloud's time service.
- Time source – Google Cloud provides NTP to Compute Engine instances through the metadata server at
metadata.google.internal. This service is backed by Google's fleet of atomic clocks and GPS receivers distributed across Google data centers, providing a Stratum-1 (highest-accuracy) NTP time source. Google Public NTP (time.google.com) exposes the same time source externally. - Scope – Clock sync applies to all Optimizely-managed servers, including event ingestion endpoints (such as
logx.optimizely.com), the CDN-hosted datafile infrastructure, and Optimizely application and API servers. - Timestamp format – All server-side timestamps use UTC. Feature Experimentation SDKs generate event timestamps on the client side when events are created. Webhook payloads include Unix epoch timestamps, and scheduled changes use ISO 8601 format with UTC.
Sync your local clocks
Feature Experimentation SDKs generate event timestamps locally. For example, impression and conversion events are timestamped when the SDK creates them, not when Optimizely servers receive them. Accurate system clocks are important because clock drift on your servers can cause event timestamps to diverge from Optimizely server-side timestamps, affecting experiment result accuracy and event correlation.
Batched events dispatch on a flush interval (for example, every one second in browsers or every 30 seconds for server-side SDKs). If local clocks drift, the gap between event creation and server receipt timestamps can complicate debugging and compliance auditing. See event batching for more information.
To maintain timestamp consistency between your systems and Feature Experimentation, sync your local clocks with a reliable NTP time source:
- Google Public NTP (
time.google.com) – Recommended because it matches the time source used by Optimizely infrastructure. - NTP Pool Project (
pool.ntp.org) – A widely available public NTP source. - Your organization's internal NTP infrastructure – Use this if your organization maintains its own time servers.
NoteSyncing to a common NTP source helps ensure your events, Optimizely logs, and third-party analytics integrations share a consistent time reference and support requirements such as ISO 27017.
Technical vulnerability management for Experimentation
Vulnerability management responsibilities are shared:
- Optimizely responsibility – Identifying, patching, monitoring, and remediating platform-level vulnerabilities. This includes infrastructure and the core platform and SDK codebase, with shared responsibility with Google Cloud as the infrastructure vendor where applicable.
- Customer responsibility – Identifying and remediating vulnerabilities in custom application code, SDK implementations, and configurations.
NoteCells marked with an asterisk (*) indicate Google Cloud shares responsibility for this area, in addition to Optimizely, as the infrastructure and network vendor.
| Area | Optimizely and Google Cloud responsibility | Customer responsibility |
|---|---|---|
| Infrastructure vulnerability scanning * | Perform regular scans on underlying cloud infrastructure, containers, and platform components. * | Not applicable. |
| Infrastructure patching * | Apply security patches and updates to infrastructure, runtime, and managed services. * | Not applicable. |
| Application code vulnerabilities | Identify and remediate vulnerabilities in SDK and platform code. | Identify and remediate vulnerabilities in code that uses Experimentation SDKs. |
| Third-party security * | Ensure platform-level integrations are secure. * | Assess and manage vulnerabilities in third-party APIs, SDKs, and integrated services. |
| Penetration testing * | Conduct periodic penetration testing of the Experimentation platform. * | Conduct testing on customer-specific applications (with provider approval if required). |
| Vulnerability remediation (Experimentation platform) | Remediate vulnerabilities within defined service level objectives (SLOs). | Not applicable. |
| Identity and Access Management (IAM) * | Provide a secure IAM framework. * | Configure roles, permissions, and user access correctly. Ensure that multi-factor authentication (MFA) and single sign-on (SSO) are enabled. |
| Monitoring and detection * | Monitor, detect, and respond to threats in the Experimentation platform. * | Monitor application-level logs, suspicious activity, and integrations. |
| Disclosure and communication | Notify customers of actions required for known vulnerability remediation. | Report discovered vulnerabilities in your applications and integrations. |
User IDs and attributes
User IDs identify the unique users in your tests. In a production setting, it is especially important to carefully choose the type of user ID and set a broader strategy for maintaining consistent IDs across channels. See Handle user IDs.
Attributes let you target users based on specific properties. In Feature Experimentation, you can define which attributes should be included in a test. Then, in the code itself, you can pass an attribute dictionary on a per-user basis to the SDK, which will determine which variation a user sees.
NoteAttribute fields and user IDs are always sent to Optimizely’s backend through impression and conversion events. You must responsibly handle fields (for example, email addresses) that may contain personally identifiable information (PII). Many customers use standard hash functions to obfuscate PII.
Integrations
Build custom integrations with Optimizely Feature Experimentation using a notification listener. Use notification listeners to programmatically observe and act on various events within the SDK and enable integrations by passing data to external services.
The following are a few examples:
- Send data to an analytics service and report that user_123 was assigned to variation A.
- Send alerts to data monitoring tools like New Relic and Datadog with SDK events to better visualize and understand how A/B tests can affect service-level metrics.
- Pass all events to an external data tier, like a data warehouse, for additional processing and to leverage business intelligence tools.
QA and test
Before you go live with your experiment, review the following documentation:
- QA and troubleshoot
- QA checklist
- Choose QA tests
- Allowlist
- Use a QA audience
- Use forced bucketing
- Troubleshoot
- History
If you have questions, contact Support. If you think you have found a bug, file an issue in the SDK’s GitHub repository.
Updated 8 days ago