How bucketing works
Overview of how Optimizely Feature Experimentation assigns users to a flag variation.
Bucketing is the process of assigning users to a flag variation based on the flag rules. The Optimizely Feature Experimentation SDKs evaluate user IDs and attributes to determine which variation each user sees.
Bucketing is:
- Deterministic – The SDK hashes the user ID to produce a consistent bucket assignment. A returning user always sees the same variation across sessions and devices.
- Sticky unless reconfigured – Bucket assignments persist as long as the flag rule configuration does not change. If you reconfigure a running flag rule—for example, by reducing traffic to 0% and then increasing it again—users may be reassigned to different variations. To prevent this, implement a user profile service.
How users are bucketed
The SDK uses the MurmurHash function to hash the user ID and experiment ID into an integer. That integer maps to one of 10,000 buckets, and each bucket corresponds to a variation (or no variation, if the user falls outside the experiment's traffic allocation). Because MurmurHash is deterministic, the same user ID always maps to the same bucket.
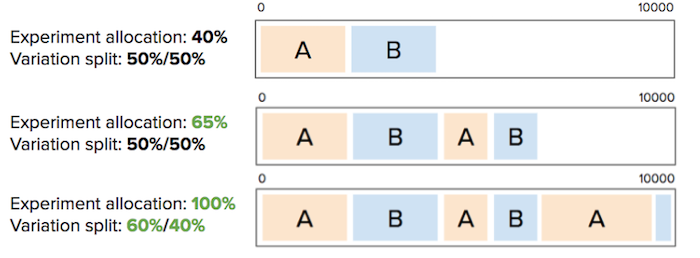
For example, imagine an experiment with two variations (A and B), 40% total traffic allocation, and a 50/50 split between variations:
- Buckets 0–1999 → variation A (20%)
- Buckets 2000–3999 → variation B (20%)
- Buckets 4000–9999 → not in the experiment (60%)
If a user hashes to bucket 1083, they always land in bucket 1083 and always see variation A.
Because bucketing happens in memory, there is no network call to an external service. This also means bucketing works consistently across channels, languages, and low-connectivity environments.
Traffic changes and rebucketing
You can increase traffic on a running experiment without rebucketing existing users—new users fill the expanded bucket range while existing assignments stay the same.
However, if you decrease traffic and then increase it again, Optimizely resets the bucket ranges and users may be reassigned to different variations. This can cause a sample ratio mismatch and invalidate your experiment results. If you need to pause an experiment to troubleshoot, pause the rule instead of reducing traffic to 0%.
Example
The following example shows how Optimizely preserves bucket ranges when you change traffic on a running experiment.
Suppose you have an experiment with two variations (A and B), 40% total traffic, and a 50/50 split. If you change the experiment allocation to any percentage except 0%, Optimizely preserves all variation bucket ranges whenever possible so that users are not rebucketed into other variations.
- Increase traffic (40% → 60%) – Optimizely preserves the existing bucket ranges and adds new buckets for the additional traffic. Existing users keep their variation assignments.
- Add a variation and increase traffic – Optimizely assigns new buckets to the new variation without reassigning existing users.
- Reduce traffic to 0%, then increase (40% → 0% → 50%) – Optimizely does not preserve bucket ranges. When traffic goes to 0%, all assignments reset. Increasing traffic again starts bucketing from scratch—users may land in different variations than before.
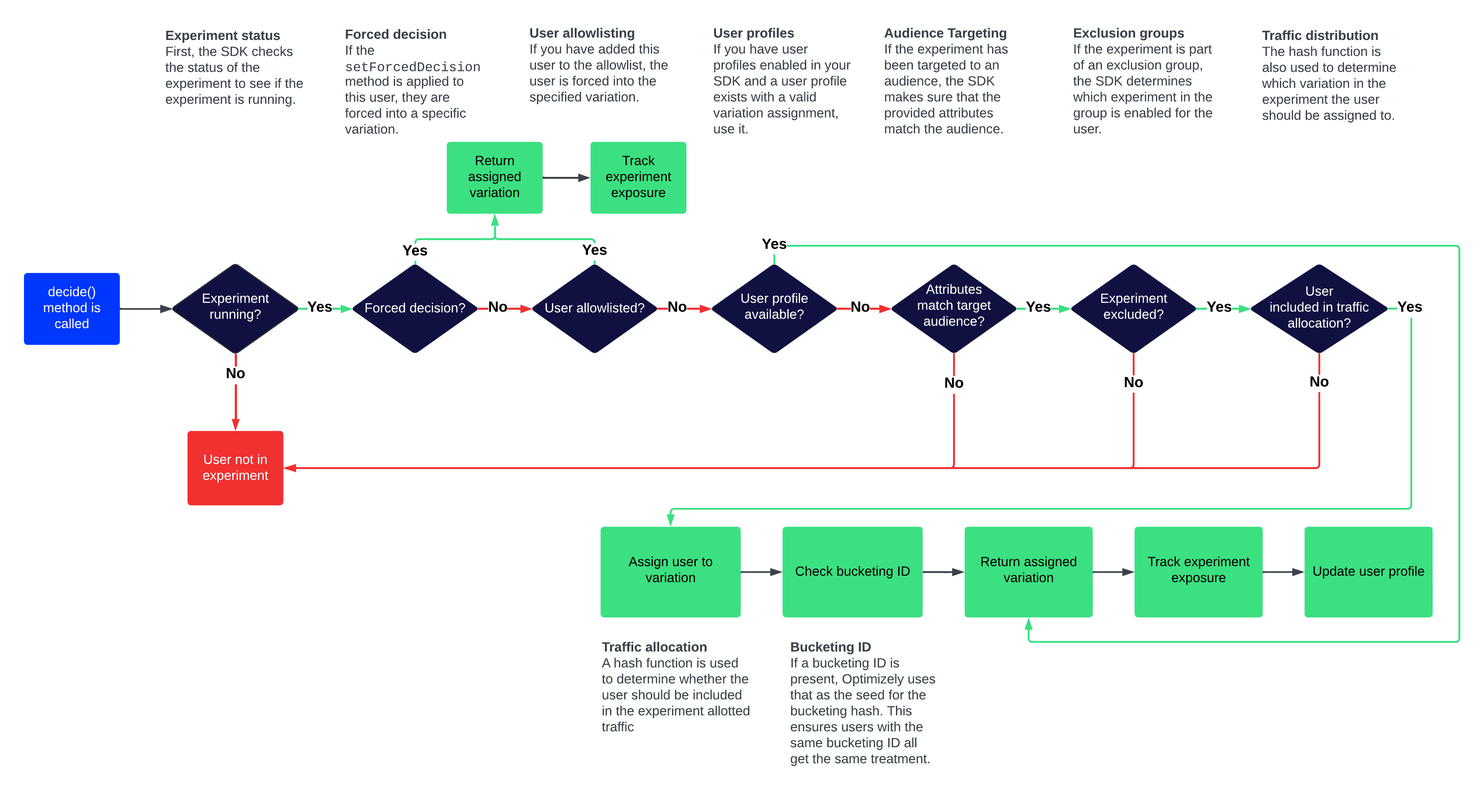
End-to-end bucketing workflow
The following table shows the evaluation order of each bucketing method:
| User bucketing method | evaluates after these: | evaluates before these: |
|---|---|---|
| Forced variation |
|
|
| User allowlisting |
|
|
| User profile service |
|
|
| Exclusion groups |
|
|
| Traffic allocation |
|
|
ImportantIf multiple bucketing methods apply to the same user, the method evaluated first takes priority.
The SDK evaluates a decision in the following order. Each step can short-circuit the process—if a step returns a variation, the remaining steps are skipped.
-
Your code calls
Decideand the SDK begins evaluating. -
The SDK checks that the flag rule is running. If it is not, the SDK returns the default variation.
-
The SDK checks for a forced decision. If one exists, the user is assigned to that variation immediately.
-
For experiment rules, the SDK checks the allowlist. If the user ID is on the list, they are assigned to the specified variation.
-
The SDK checks the User Profile Service (if configured). If a stored assignment exists for this user, that variation is returned.
-
The SDK evaluates audience conditions against the user's attributes. If the user does not match the audience, they are excluded from the experiment.
-
The SDK evaluates any exclusion groups. If the user is assigned to a different experiment in the group, they are excluded from this one.
-
The SDK hashes the user ID (or bucketing ID, if configured) with the experiment ID to produce a bucket number. Based on the traffic allocation set in the Optimizely app, the bucket maps to a variation assignment.
Click to enlarge
Updated 7 days ago