
Interactions between flag rules
Describes flag rules and how they interact for Optimizely Feature Experimentation.
Note
This topic is most helpful if you run experiments and need an in-depth understanding of how your audiences bucket into both experiments and targeted deliveries.
Rules contain the experiment and targeting logic within a flag. Rules describe what variation the flag should deliver to a given user. A ruleset is the collection of rules associated with a flag.
Rules can be
- Experiments – A/B tests or multi-armed bandit optimizations
- Flag deliveries – Targeted delivery
When multiple rules have overlapping audiences in the same ruleset, interactions between these rules can occur. For information about how to protect from interaction effect, see Mutually exclusive experiments.
Rule evaluation sequence
Feature Experimentation evaluates whether a user qualifies for rules from the top to the bottom of the ruleset. Experiments are evaluated first, followed by flag deliveries, then the Then, for everyone else rule.
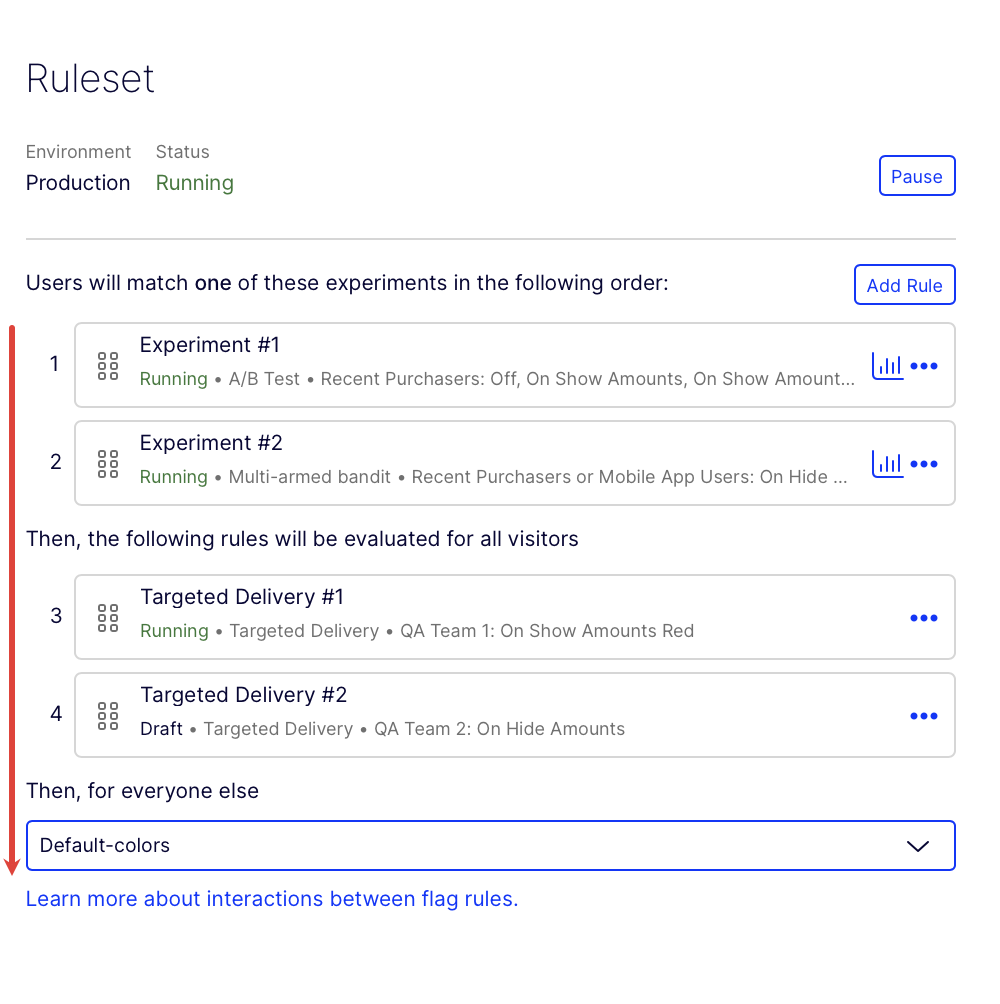
Note
The Then, for everyone else rule is a single variation.
If you have no rules, the Then, for everyone else label changes to For everyone in
[THE_CURRENT_ENVIRONMENT].
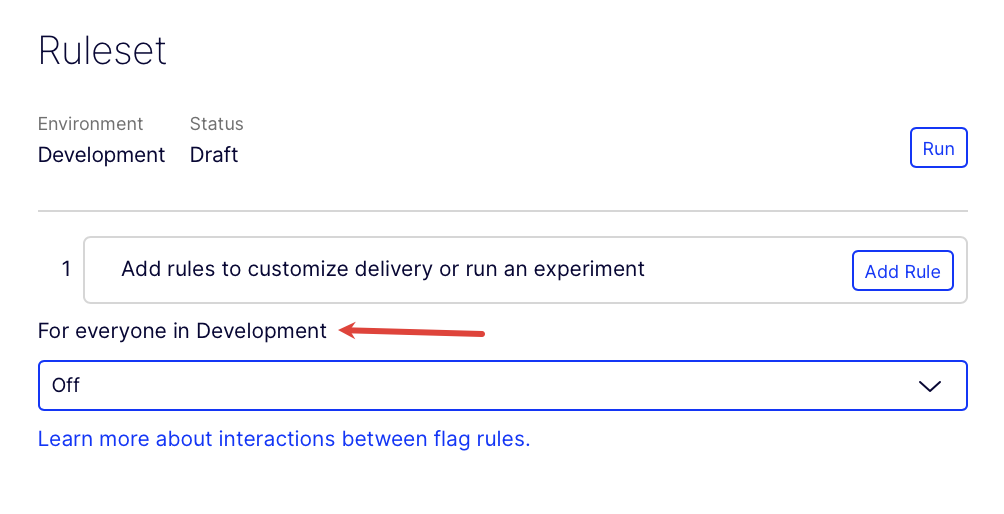
Feature Experimentation evaluates the user to see if they qualify for the rule depending on the audience criteria.
The audience criteria checks
- Does the user qualify for the flag's audiences?
- Was the user bucketed into the traffic allocation?
If a user does not qualify for a rule because they failed the audience criteria check, they "roll down" to the next rule, and the process begins again.
Warning
For flag delivery rules only, if the user matches the rule's audience but is not bucketed into its traffic allocation, Feature Experimentation jumps to the last rule (the Then, for everyone else rule) instead of evaluating the next flag delivery rule.
When a user qualifies for a rule and receives a variation, Feature Experimentation halts further evaluation immediately.
The following diagram shows this behavior in detail:
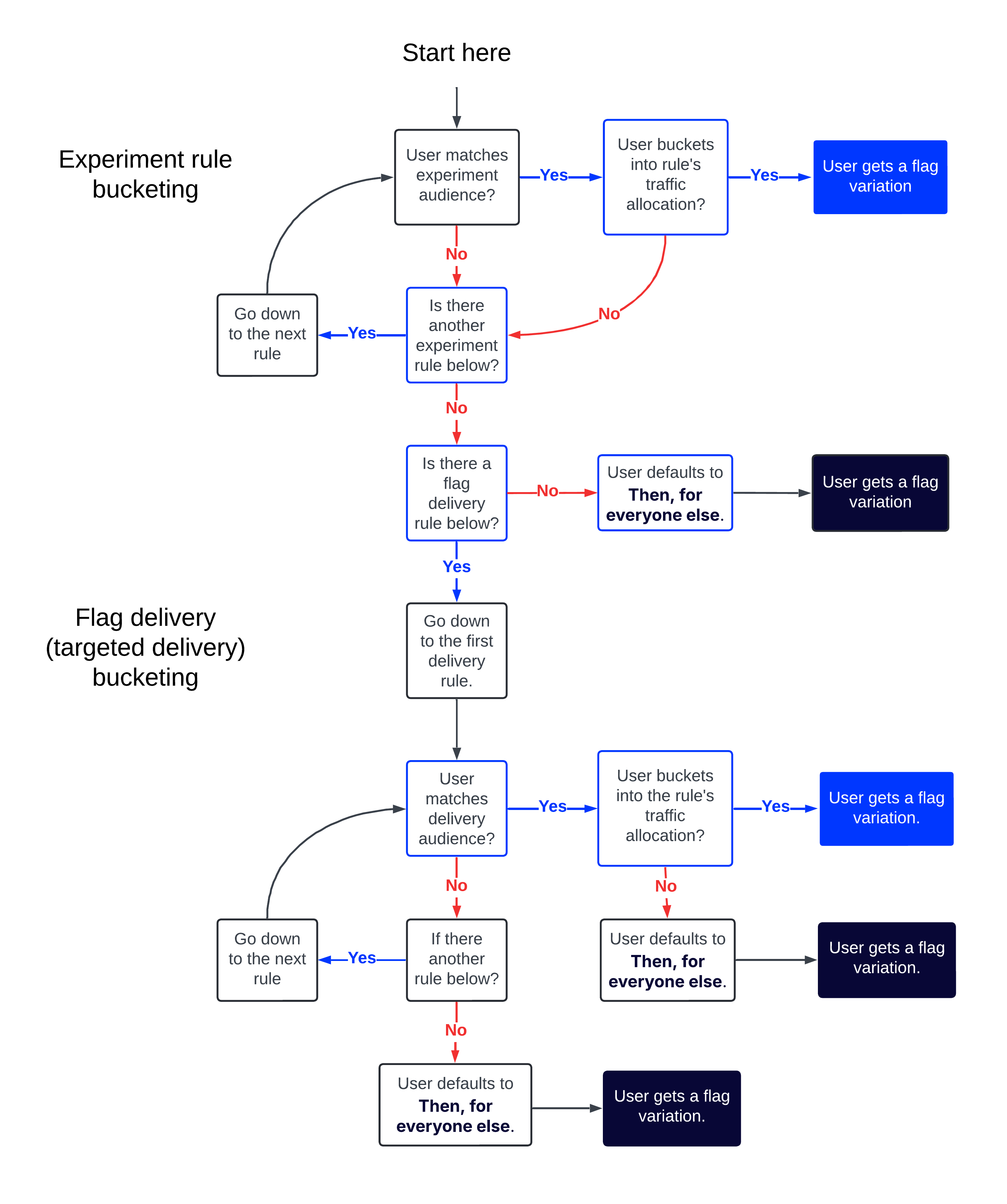
The following table elaborates on the preceding diagram by showing all possible outcomes for audiences and traffic conditions for a ruleset with one experiment rule and one delivery rule.
| User | Experiment audience | Experiment traffic | Targeted Delivery audience | Targeted Delivery traffic | Bucketed into |
|---|---|---|---|---|---|
| user1 | pass | pass | N/A | N/A | Experiment rule |
| user2 | pass | fail | pass | pass | Targeted Delivery rule |
| user3 | fail | N/A | pass | pass | Targeted Delivery rule |
| user4 | fail | N/A | pass | fail | Then, for everyone else rule |
| user5 | fail | N/A | fail | N/A | Then, for everyone else rule |
Why are experiments and flag delivery rules evaluated differently?
Experiments – The main goal of experiments is to collect clean data to compare different variations of a feature. If you have multiple experiments for the same flag, a user has a chance to qualify for each one sequentially. This lets you test different hypotheses or variations without overlap.
Flag deliveries – Deliveries roll out a feature to specific audiences in a controlled way after the experiments were evaluated. This behavior ensures users are not accidentally included in a delivery they should not be part of. It prioritizes controlled rollout and prevents unintended feature exposure.
Rule evaluation examples
Multiple experiments examples
Example 1
User A encounters a flag with two experiment rules and a Then, for everyone else variation.
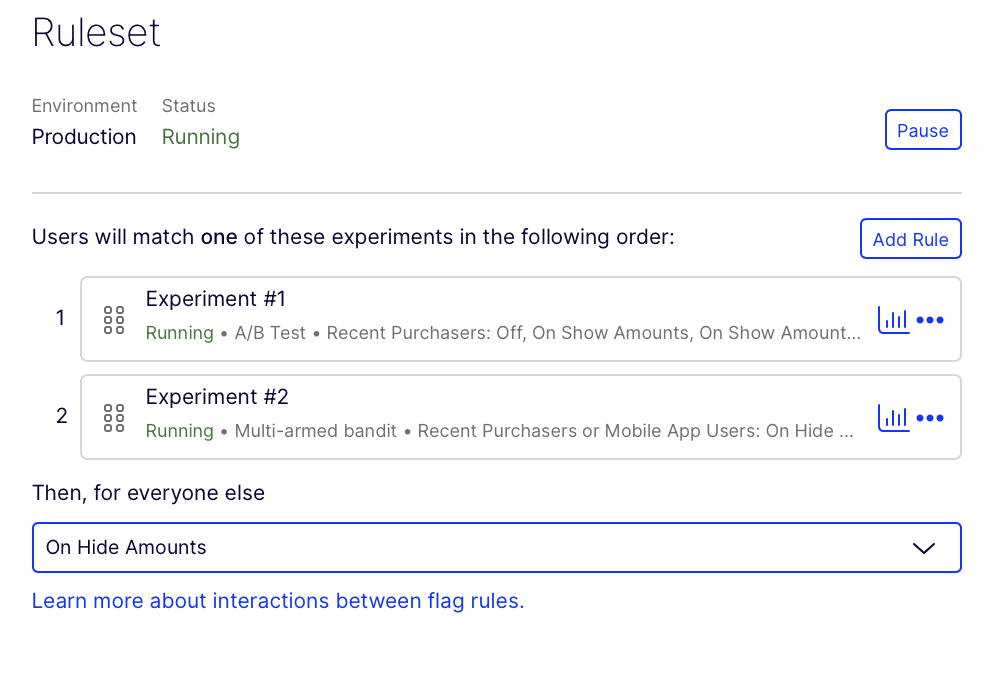
Feature Experimentation evaluates User A for Experiment #1. User A qualifies for the audience, but they are not bucketed because they do not qualify for the traffic allocation. This means they are not randomly assigned to the experiment and fail the audience criteria for Experiment #1.
Feature Experimentation immediately then checks if User A passes Experiment #2's audience check. User A passes the audience criteria for Experiment #2, and they are bucketed into that rule.
Note
User A is bucketed in Experiment #2 because, for experiments, failing bucketing does not prevent users from moving to subsequent rules.
Example 2
User B encounters the same flag as User A, which has two experiment rules and a Then, for everyone else variation.
Feature Experimentation evaluates User B for Experiment #1. User B qualifies for the audience, but they are not bucketed because they do not qualify for the traffic allocation. This means they are not randomly assigned to the experiment and fail the audience criteria for Experiment #1.
Feature Experimentation immediately then checks if User B passes Experiment #2's audience check. User B again fails the audience criteria. User B is bucketed into the Then, for everyone else variation.
Multiple experiments with multiple flag delivery rules examples
Example 1
User C encounters a flag with two experiment rules, two flag delivery rules, and a Then, for everyone else variation.
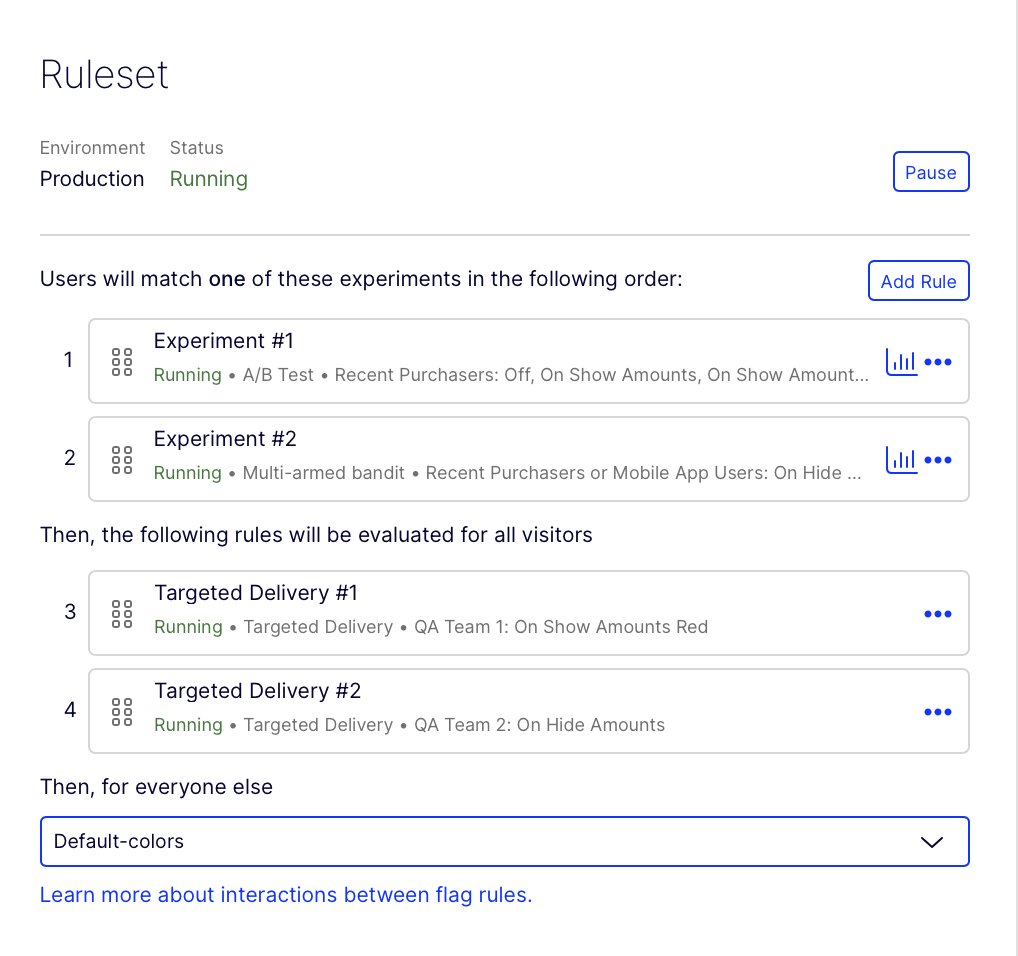
Feature Experimentation evaluates User C for Experiment #1. User C does not qualify for the audience and is not bucketed. Feature Experimentation then evaluates if User C should be part of Experiment #2. They are not part of the audience, so they are not bucketed.
Feature Experimentation evaluates if they should be part of Targeted Delivery #1. They are part of the audience and are in the traffic allocation, so they are also bucketed in Targeted Delivery #1.
Example 2
User D encounters the same flag as User C with two experiment rules, two flag delivery rules, and a Then, for everyone else variation.
Feature Experimentation evaluates User D for Experiment #1. User D qualifies for the audience but is not in the traffic allocation, so they are not bucketed. Feature Experimentation then evaluates if User D qualifies for Experiment #2. Again, User D qualifies for the audience but is not in the traffic allocation, so they are not bucketed.
Feature Experimentation evaluates User D for the flag delivery rules. User D is part of the audience for Targeted Delivery #1, but they are not in the traffic allocation, so they are not bucketed into the flag delivery rule. Feature Experimentation does not evaluate if they would be in Targeted Delivery #2. User D is bucketed into the Then, for everyone else rule. They receive the Default-colors variation.
Note
User D is not evaluated for Targeted Delivery #2 because Feature Experimentation stops checking if the user qualifies for flag delivery rules if they are not bucketed due to not being in the traffic allocation.
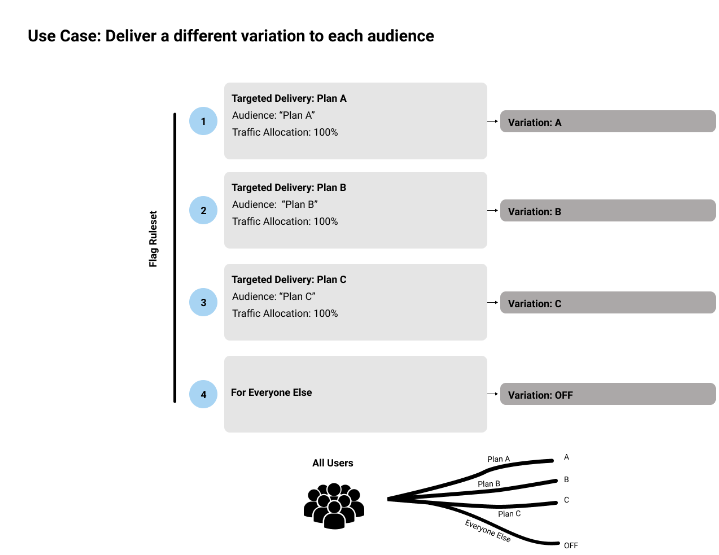
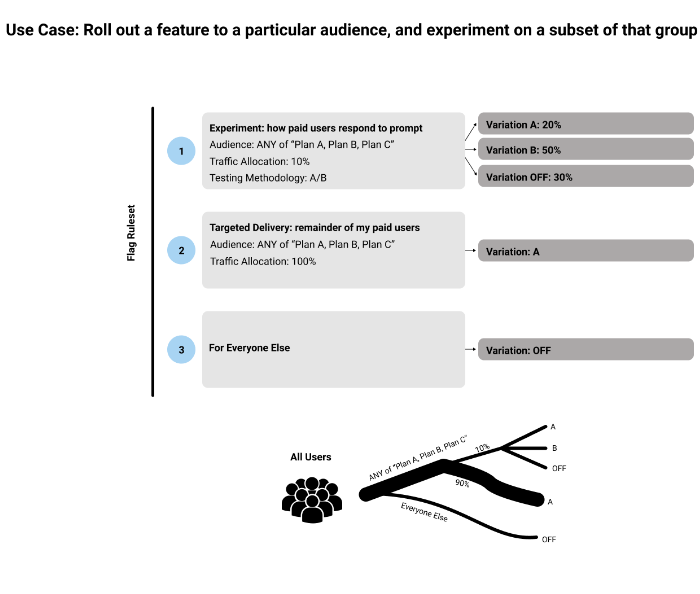
Rulesets and total traffic
The following diagrams illustrate some of the ways that traffic can be split across flag rules, depending on the traffic allocations and audiences you set:
Updated 5 months ago