How bucketing works
This topic describes how bucketing, the process of assigning users to a feature rollout or an experiment, works for Optimizely Full Stack Experimentation.
Bucketing is the process of assigning users to a feature rollout or to different variations of an experiment.
Bucketing is:
- Deterministic: A user sees the same variation across all devices they use every time they see your flag variation, thanks to how we hash user IDs. A single user is not randomly re-evaluated every time they see your experiment, in other words: they always get the same flag variation or flag on/off experience.
- Sticky unless reconfigured: If you reconfigure a "live," running experiment, for example by decreasing and then increasing traffic, a user may get rebucketed into a different flag variation.
| Resource | description |
|---|---|
| How does Full Stack random bucketing work? | 4-minute video explaining how users are hashed into experiments and rollouts buckets in Optimizely |
How users are bucketed
The Full Stack SDKs evaluate user IDs and attributes to determine which variation they should see.
During bucketing, the SDKs rely on the MurmurHash function to hash the user ID and experiment ID to an integer that maps to a bucket range, which represents a variation. MurmurHash is deterministic, so a user ID will always map to the same variation as long as the experiment conditions do not change. This also means that any SDK will always output the same variation, as long as user IDs and user attributes are consistently shared between systems.
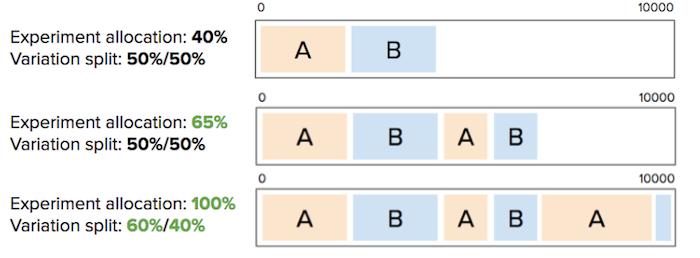
For example, imagine you are running an experiment with two variations (A and B), with an experiment traffic allocation of 40%, and a 50/50 distribution between the two variations. Optimizely will assign each user a number between 0 and 10000 to determine if they qualify for the experiment, and if so, which variation they will see. If they are in buckets 0 to 1999, they see variation A; if they are in buckets 2000 to 3999, they see variation B. If they are in buckets 4000 to 10000, they will not participate in the experiment at all. These bucket ranges are deterministic: if a user falls in bucket 1083, they will always be in bucket 1083.
This operation is highly efficient because it occurs in memory, and there is no need to block on a request to an external service. It also permits bucketing across channels and multiple languages, as well as experimenting without strong network connectivity.
See also Interactions between feature tests and rollouts.
Changing traffic can rebucket users
The most common way to change "live" traffic for an enabled feature flag is to increase it. In this scenario, you can monotonically increase overall traffic without rebucketing users.
However, if you change traffic non-monotonically (for example, decreasing, then increasing traffic), then your users can get rebucketed. In an ideal world, you avoid non-monotonical traffic changes for a running experiment, because it can result in statistically invalid metrics. One exception is if you're using our Stats Accelerator (typically as part of a mature progressive delivery culture). If you're using Stats Accelerator or otherwise need to change experiment traffic "live", you can ensure sticky user variation assignments by implementing a user profile service. For more information, see user profile service. User profile service is only compatible with experiments, not with rollouts.
Reconfiguring rollouts traffic | Do users get rebucketed? |
|---|---|
Increase overall traffic monotonically | No |
Change traffic non-monotonically | Yes |
Reconfiguring experiment traffic | Do users get rebucketed? * |
|---|---|
Increase overall traffic allocation monotonically | No |
Pause/play variations in the experiment | Yes |
Change overall traffic allocation non-monotonically | Yes |
Change traffic distribution between variations or | Yes |
Reconfiguring mutually exclusive experiment groups | Do users get rebucketed? * |
|---|---|
Increase overall traffic allocation for each experiment monotonically | No |
Pause/play experiments in the group | No |
Change overall traffic allocation for each experiment | Yes |
Change traffic distribution between experiments or add/remove | Yes |
To avoid rebucketing, implement a user profile service. User profile service is not compatible with rollouts.
Rebucketing example
Let us walk through an example in detail of how Optimizely attempts to preserve bucketing if you reconfigure a running experiment.
Imagine you are running an experiment with two variations (A and B), with a total experiment traffic allocation of 40%, and a 50/50 distribution between the two variations. In this example, if you change the experiment allocation to any percentage except 0%, Optimizely ensures that all variation bucket ranges are preserved whenever possible to ensure that users will not be re-bucketed into other variations. If you add variations and increase the overall traffic, Optimizely will try to put the new users into the new variation without re-bucketing existing users.
To continue the example, if you change an experiment variation allocation from 40% to 0%, Optimizely will not preserve your variation bucket ranges. After changing the experiment allocation to 0%, if you change it again, perhaps to 50%, Optimizely starts the assignment process for each user from scratch: Optimizely will not preserve the variation bucket ranges from the 40% setting.
To completely prevent variation reassignments, implement sticky bucketing with the User Profile Service, which uses a caching layer to persist user IDs to variation assignments.
End-to-end bucketing workflow
The following table highlights how various user-bucketing methods interact with each other:
User bucketing method | evaluates after these: | evaluates before these: |
|---|---|---|
Forced variation |
|
|
User whitelisting |
|
|
User profile service |
|
|
Exclusion groups |
|
|
Traffic allocation |
|
|
ImportantIf there is a conflict over how a user should be bucketed, then the first user-bucketing method to be evaluated overrides any conflicting method.
For a comprehensive bucketing view, let us walk through how the SDK evaluates a decision. This chart explores all possible factors, including beta features like bucketing ID.
- The Activate or Is Enable Feature call is executed, and the SDK begins its bucketing process.
- The SDK ensures that the experiment is running.
- It compares the user ID to the whitelisted user IDs. Whitelisting is used to force users into specific variations. If the user ID is found on the whitelist, it will be returned.
- If provided, the SDK checks the User Profile Service implementation to determine whether a profile exists for this user ID. If it does, the variation is immediately returned and the evaluation process ends. Otherwise, proceed to step 5.
- The SDK examines audience conditions based on the user attributes provided. If the user meets the criteria for inclusion in the target audience, the SDK will continue with the evaluation; otherwise, the user will no longer be considered eligible for the experiment.
- The hashing function returns an integer value that maps to a bucket range. The ranges are based on the traffic allocation breakdowns set in the Optimizely dashboard, and each corresponds with a specific variation assignment.
- (Beta) If the bucketing ID feature is used, the SDK will hash the bucketing ID (instead of the user ID) with the experiment ID and return a variation.
