Import/export data using Amazon S3
You can import and export your customer, product, order, event, and custom data into Optimizely Data Platform (ODP) using Amazon S3.
Amazon S3 is a simple storage service that you can use to store and retrieve data from anywhere on the web. Similar to FTP/SFTP, it lets external tools and services store and retrieve large amounts of data.
Recommended use
You should use Amazon S3 for uploads of data to ODP on a scheduled basis from external systems. Examples of recurring uploads include:
- Product feeds
- Customer updates
- List subscriptions
- Consent updates
ImportantCSV imports using Amazon S3 must adhere to the file format and name requirements outlined in Import data using CSV.
Generate Amazon S3 credentials
To use Amazon S3, you need the bucket (location) you want to access and the access key/secret for authentication. To retrieve these:
-
Go to Data Setup > Integrations.
-
Select the AWS integration.
-
Click Generate Access Keys.
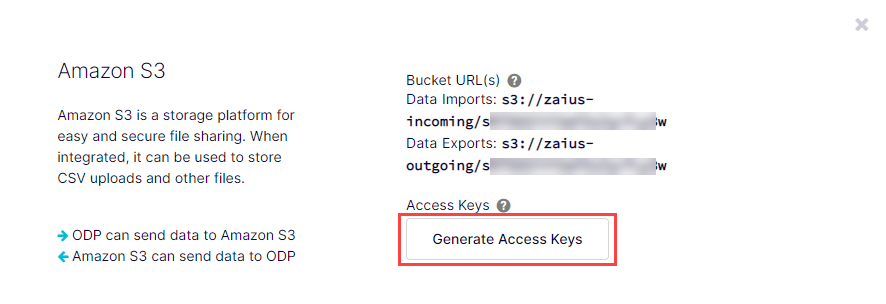
Locate your access keys and bucket URLs
Your Key ID and Secret Access Key display below Access Keys in Data Setup > Integrations > AWS, which you can copy and paste into the command-line interface or a third-party application to complete the Amazon S3 integration with ODP.
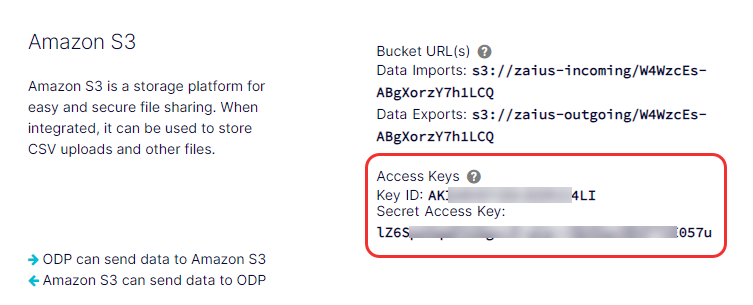
Your Amazon S3 bucket URLs also display here. All clients have an Amazon S3 bucket for imports and another for exports. The structure of the bucket URLs is shown below:
- Data imports –
s3://zaius-incoming/your_tracker_id - Data exports –
s3://zaius-outgoing/your_tracker_id
For additional help from AWS, you can install the AWS CLI tools and use the S3 command line reference guide.
ImportantData in the Amazon S3 buckets expires after 7 days.
Import from Amazon S3 to ODP using command-line
After you place a file in your Zaius-incoming bucket, ODP automatically imports it. You can fully automate the import process if you regularly create data for imports and can schedule to add that data to your S3 bucket.
Use the following command to copy a local file to Amazon S3:
aws s3 cp zaius\_customers.csv s3://zaius-incoming/<your tracker ID>/ --sseUse the following command to copy a directory of files to Amazon S3:
aws s3 sync /tmp/yourlocaldir/ s3://zaius-incoming-temp/<your tracker ID>/ --sseExport from ODP to Amazon S3 using command-line
- Run a Start Export Job API request for your desired export format (CSV or parquet), delimiter (comma, tab, pipe), and objects.
- Copy the
pathvalue from the API response body. For example:s3://zaius-outgoing/lz3CnPijk15xYhTw7DU4wx/data-exports/3a44cik3-e981-53bf-6499-f9fc6851fae - Run the following command, replacing
<PATH>with thepathvalue you copied in step 2. This retrieves all Amazon S3 files for the export you requested in step 1.aws s3 cp <PATH> . --recursive --sseNoteUsing the example from step 2:
aws s3 cp s3://zaius-outgoing/lz3CnPijk15xYhTw7DU4wx/data-exports/3a44cik3-e981-53bf-6499-f9fc6851fae . --recursive --sse
This command outputs the contents of your requested export ID to your current directory. To specify a location, replace . with the directory path. For example, to output the directory to your desktop, specify one of the following, depending on your operating system:
- OS X –
/Users/<name>/Desktop - Windows –
C:\\Users\\<name>\\Desktop (Windows)
NoteODP exports are a set of files in a directory folder identified by the export ID you provide. Be sure you transfer the entire directory to get the entirety of the export.
Import/export from Amazon S3 using a third-party application
You can use whichever third-party application you prefer. Common developer tools you can use to perform uploads to Amazon S3 include:
- Cyberduck (Windows and Mac) – marketer friendly
- AWS CLI (Windows, Mac, and Linux)
- AWS SDKs (Java, Python, Node.js, PHP, and more)
The following instructions are for Cyberduck, which is a free cloud storage browser that you can use with Amazon S3.
-
Download and launch a free tool, like Cyberduck.
-
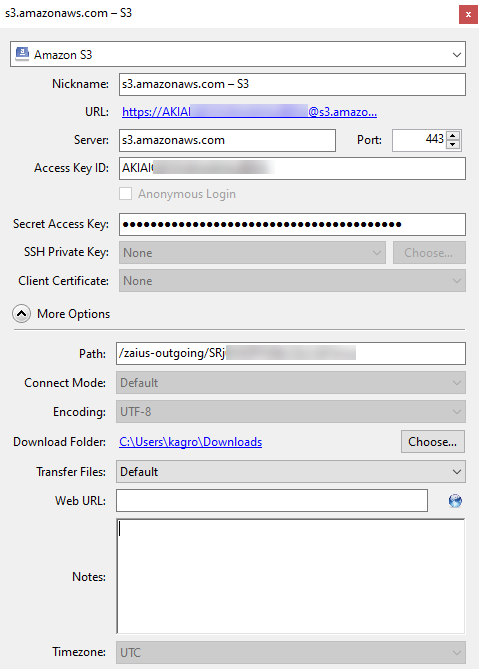
In Cyberduck, expand Action and select New Bookmark.
-
Select Amazon S3 from the drop-down list at the top of the pop-up window.
-
(Optional) Enter a Nickname.
-
Enter the Access Key ID (the Key ID from ODP).
-
Enter the Secret Access Key (the Secret Access Key from ODP).
-
Expand More Options and enter the Path (the Data Exports bucket URL from ODP). Remove
s3:/from the beginning of the URL, leaving only one forward slash.NoteTo locate your exact URL, go to Account Settings > Integrations > AWS. Under Bucket URL(s), copy the Data Exports value.
-
Close the pop-up window to save the new bookmark.
NoteFor information about using Cyberduck to import AWS files, see their documentation.
Updated about 1 month ago